Evals in Production
Quick Summary
deepeval allows you to live monitor LLM responses in production, which you can enable real-time evaluations on. By tracking responses, you can leverage our hosted evaluation infrastructure to identify unsatisfactory LLM responses, have human annotators send feedback to such responses, and improve your evaluation dataset over time.
Monitor Live Responses
To monitor LLM responses, use the deepeval.track(...) method in your LLM application to start tracking responses.
import deepeval
# At the end of your LLM call,
# usually in your backend API handler
deepeval.track(
event_name="Chatbot",
model="gpt-4",
input="input",
response="response",
distinct_id="...",
conversation_id="...",
# for RAG pipelines
retrieval_context=["..."],
completion_time=8.23,
token_usage=134,
token_cost=0.23,
fail_silently=True
)
The track() function takes in the following arguments:
event_name: typestrspecifying the event trackedmodel: typestrspecifying the name of the LLM model usedinput: typestrresponse: typestr- [Optional]
distinct_id: typestrto identify end users using your LLM application - [Optional]
conversation_id: typestrto group together multiple messages under a single conversation thread - [Optional]
completion_time: typefloatthat indicates how many seconds it took your LLM application to complete - [Optional]
retrieval_context: typelist[str]that indicates the context that were retrieved in your RAG pipeline - [Optional]
token_usage: typefloat - [Optional]
token_cost: typefloat - [Optional]
fail_silently: typebool, defaults to True. You should try setting this toFalseif your events are not logging properly.
Please do NOT provide placeholder values for optional parameters. Leave it blank instead.
Send Human Feedback
coming soon...
Responses on Confident AI
Confident offers an observatory to view responses and identify ones where you want to augment your evaluation dataset with.
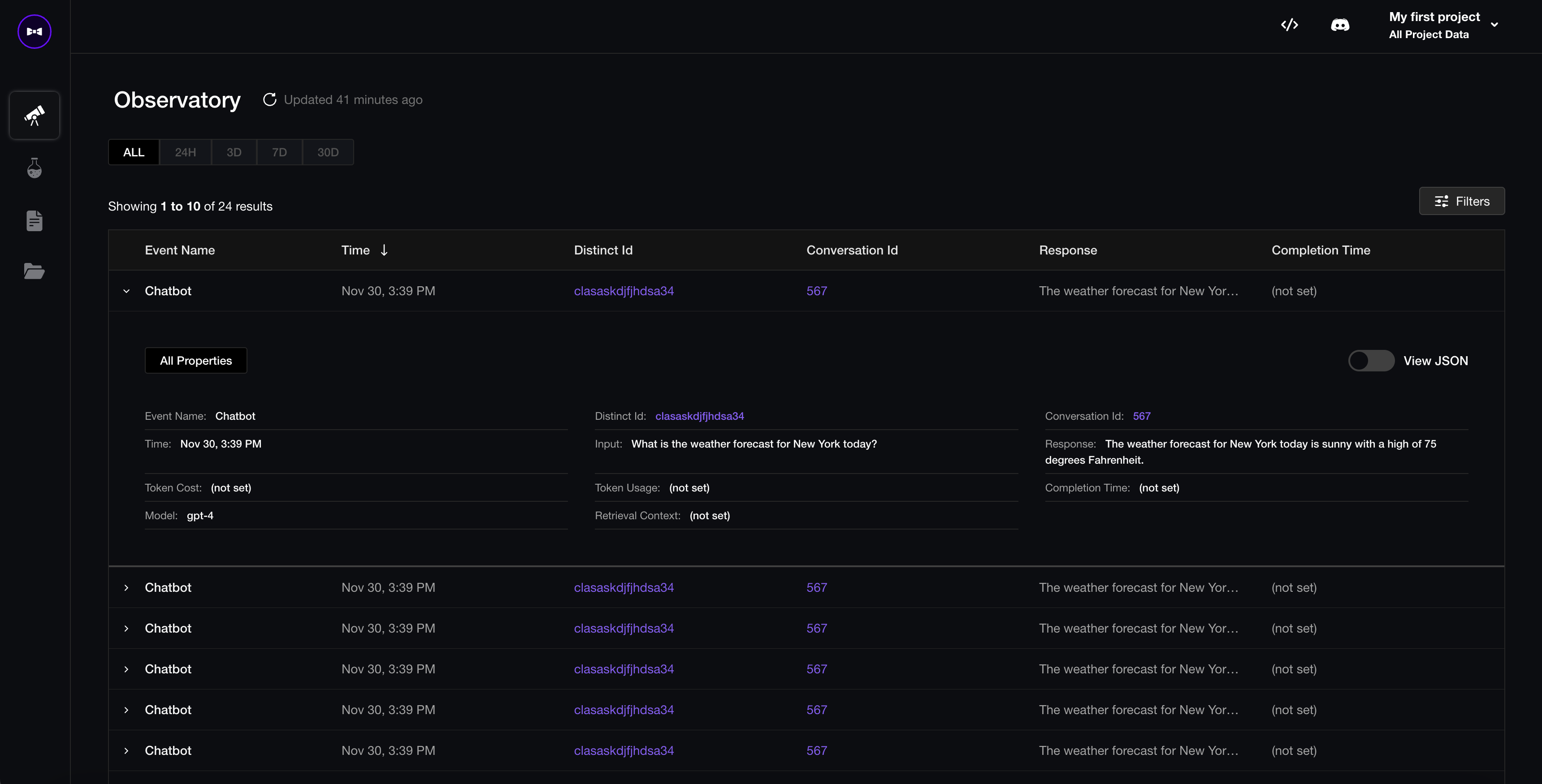
If you're building an LLM chatbot, you can also view entire conversation threads via the conversation_id.

Enable Real-Time Evals
To monitor how your LLM application is performing over time, and be alerted of any unsatisfactory LLM responses in production, head to the "projects details" section via the left navigation drawer to turn on the metrics you wish to enable in production. Confident AI will automatically run evaluations for enabled metrics for all incoming events.
